
Introduction
This week in AI, OpenAI announced a significant update to GPT-4, promising to process much larger inputs – up to a staggering 128k tokens. However, the excitement was met with a dose of reality: the model still struggles with long context windows. Let’s dive into the recent findings and what this means for the future of Large Language Models (LLMs) like GPT-4 and Llama.
Understanding Context Limitations in LLMs
Large Language Models have always grappled with a key limitation: context size. Essentially, this refers to the amount of text they can consider in generating a response. Previously, we learned from earlier research that longer context windows tend to falter unless crucial information is strategically placed at the beginning or end of the input. But what about the enhanced capabilities of GPT-4?
GPT-4: Does Bigger Mean Better?
Shawn Wang, utilizing data and code from Louis Knight-Webb, embarked on experiments here to test GPT-4’s proficiency with long contexts. Jerry Liu’s data here further underscores these findings.
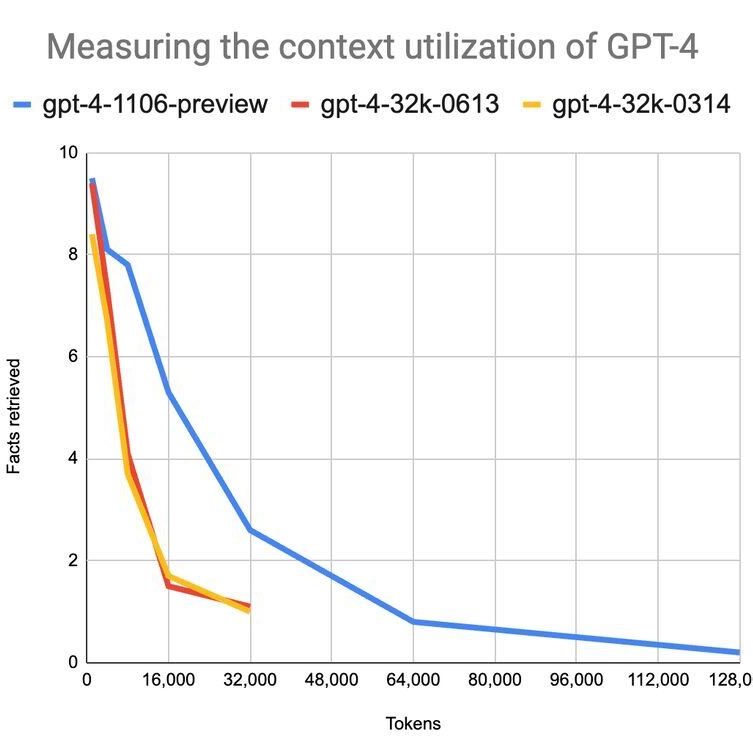
What’s clear is that GPT-4 marks a substantial leap over its predecessors. Yet, when we examine its performance graph, a pattern emerges. Around 25k tokens (roughly equivalent to 25,000 words), GPT-4 starts to falter, failing to recall half of the facts targeted in queries. This suggests that despite its advancements, GPT-4 isn’t entirely foolproof when handling extensive text inputs.
Cost vs. Utility: A Balancing Act
One cannot ignore the cost factor. Each max-length context window query in GPT-4 can set you back by over a dollar, raising questions about the practicality and efficiency of using such extensive context sizes. Does the cost justify the capabilities?
The Path Forward: Retrieval Augmented Generation
The current situation points towards Retrieval Augmented Generation (RAG) as a more viable path. RAG involves using embedding search and vector databases to filter and present only the most relevant context. This approach, while not without its complexities, aligns more closely with efficiency and practicality, especially at a larger scale.
Alternatively, fine-tuning on specific data sets, though more complex, can offer greater efficiency at scale. This approach requires more investment in model training but could yield more tailored and effective results.
Conclusion
GPT-4’s latest iteration is undoubtedly a step forward in the AI and ML field. However, its limitations in managing long context windows, alongside cost considerations, suggest that we might not be ready to discard more traditional methods like Retrieval Augmented Generation just yet. As we continue to push the boundaries of what AI can do, it’s clear that there’s still much to explore and refine in the world of LLMs.
Stay tuned for more updates and deep dives into the ever-evolving world of AI at theMind blog.